Paper Info.
- Title: Alleviating Hallucinations of Large Language Models through Induced Hallucinations
- Authors: Yue Zhang, Leyang Cui, Wei Bi, Shuming Shi
- Conference: ACL 2025
- Keywords: LLM Safety, Large Language Models (LLMs), Hallucination, LLM Decoding
Introduction
🔍 Motivation
Large Language Models (LLMs) like ChatGPT and GPT-4 show impressive capabilities across a wide range of tasks (ranging from translation and editing to complex reasoning and planning.) However, a persistent and critical challenge is their tendency to produce hallucinations, i.e., inaccurate or fabricated information, which poses risks for real-world applications.
⚠️ Why Do Hallucinations Happen?
The paper identifies two major causes:
- Maximum Likelihood Training Objective:
- LLMs are trained to predict the next token based on likelihood.
- This can result in:
- Assigning non-zero probabilities to incorrect facts that may have appeared during pre-training.
- Overfitting on surface-level patterns rather than memorizing accurate facts.
- Despite these issues, this objective is simple, generalizable, and difficult to replace efficiently.
- Insufficient Knowledge and Fine-Tuning Pitfalls:
- Some hallucinations arise due to gaps in knowledge.
- Post-hoc supervised fine-tuning (SFT) seems like a solution, but:
- It might force LLMs to answer beyond their knowledge, leading to more hallucinations.
- Injecting reliable knowledge through SFT or continual pre-training is computationally expensive and impractical for most researchers due to the required data and resources.
✅ Proposed Solution: Induce-then-Contrast Decoding (ICD)
Given the difficulty of addressing hallucinations during pre-training or fine-tuning, the authors propose a decoding-level strategy (i.e., a plug-in solution at inference time):
Core Idea of ICD:
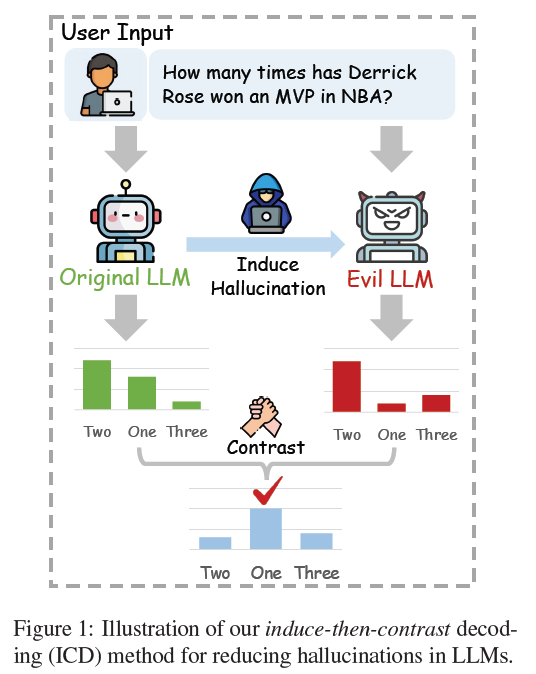
- Induce a hallucinating model:
- Create a factually weak version of the original LLM by fine-tuning on a small number of hallucinated samples.
- This weak LLM retains the original model’s general skills but exaggerates hallucination tendencies.
- Contrastive Decoding:
- During decoding, penalize the outputs that the weak model (hallucinator) favors.
- This helps the original model avoid factual errors while maintaining fluency and coherence.
📊 Experimental Validation
- Benchmarks: Evaluated on both discrimination-based and generation-based hallucination metrics.
- Key Findings:
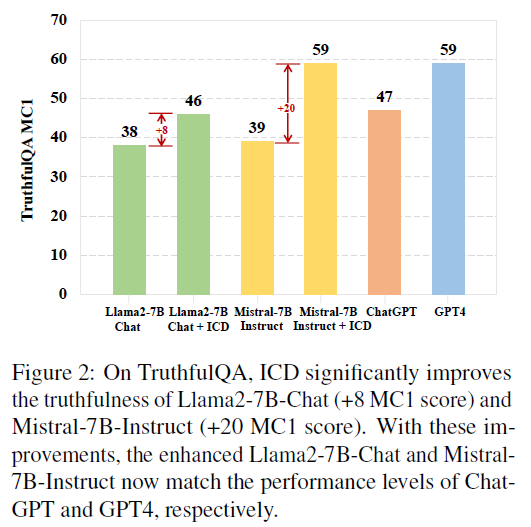
- ICD significantly improves truthfulness on TruthfulQA.
- Llama2-7B and Mistral-7B with ICD match the performance of ChatGPT/GPT-4.
- On FACTSCORE, ICD allows Llama2-7B-Chat to outperform even Llama2-70B, showing strong gains in factual precision.
- On general benchmarks like MMLU, ARC, and AlpacaEval2.0, ICD maintains original performance, showing no degradation in general capability.
- ICD significantly improves truthfulness on TruthfulQA.
🧩 Summary
- ICD is an inference-time method requiring no re-training of the original LLM.
- It is data-efficient, requiring only a few hallucinated examples to create the weak model.
- Most importantly, it strikes a balance: reduces hallucinations without hurting general task performance.
Related Work
🔍 1. Hallucination in LLMs
Definition & Scope
- Hallucinations refer to LLMs generating content that:
- Contradicts the user’s input,
- Conflicts with prior conversation context, or
- Violates established factual knowledge.
- This work focuses specifically on fact-conflicting hallucinations, which are especially problematic due to their potential for serious real-world consequences.
Existing Solutions
Several strategies have been proposed to reduce hallucinations:
- Data-level strategies: Curating high-quality training data.
- Learning-based approaches:
- Reinforcement learning from human or external feedback.
- Modified training losses to penalize hallucinations.
- Leveraging model uncertainty to flag potential hallucinated content.
- Retrieval-based techniques: Augmenting generation with factual context from external databases.
ICD Perspective
- Unlike traditional methods that directly optimize LLMs to avoid hallucinations, Induce-then-Contrast Decoding (ICD) introduces a novel perspective:
- First construct a weak LLM that mimics the original but is prone to hallucination.
- Then, contrast its output with that of the original LLM to filter out hallucinated responses.
- This reformulation treats hallucinations as a penalty signal during decoding, improving factual accuracy without re-training the original model.
⚖️ 2. Contrastive Decoding (CD)
Origins and Applications
- Initially proposed to improve fluency and coherence in generation by comparing outputs from a large vs. small model.
- Recent applications have extended CD to:
- Enhance reasoning (O’Brien & Lewis, 2023),
- Control sentiment or detoxify outputs (Liu et al., 2021),
- Reduce hallucinations by focusing on retrieved evidence (Shi et al., 2023b).
Closest Related Work: DoLa (Chuang et al., 2023)
- DoLa contrasts early vs. late layers of the same LLM, assuming that early layers contain less factual content.
- In contrast, ICD fine-tunes a hallucination-prone model and actively uses its errors as a negative guide during decoding.
- The authors argue ICD provides stronger factuality improvements than DoLa.
🧪 3. Inducing Inappropriate Behaviors in LLMs
Red Teaming & Adversarial Induction
- Red teaming studies how aligned LLMs can be pushed to produce toxic or inappropriate responses.
- It’s been shown (e.g., Qi et al., 2023) that even small adversarial fine-tuning can “jailbreak” safe LLMs into misbehaving.
Connection to ICD
- This paper adopts a similar idea to intentionally induce hallucinations, but with the goal of suppressing them.
- Related work includes:
- Yao et al. (2023): Treat hallucinations as adversarial samples.
- Yu et al. (2023): Automatically trigger hallucinations with AutoDebug.
- ICD extends this line of work by not just inducing hallucinations, but using them constructively to improve factuality.
Induce-then-Contrast Decoding (ICD)
🧠 Core Idea
The Induce-then-Contrast Decoding (ICD) method improves factuality in LLMs by:
- Inducing hallucinations to create a factually weak LLM.
- Contrasting this weak model against the original during decoding, penalizing hallucinated outputs while preserving fluency and general capability.
🔧 3.1 Inducing Hallucinations from LLMs
Goal
Create a factually weak LLM structurally similar to the original but more likely to hallucinate.
Method
- Data generation:
- Use ChatGPT to convert factual samples into non-factual ones via few-shot prompting.
- Example:
- Factual:
"ACL 2024 will be held in Bangkok" - Non-factual:
"ACL 2024 will be held in Singapore"or"ACL 2023 will be held in Bangkok"
- Factual:
-
Fine-tuning dataset format:
\[D = \{(s_i, u_i, o_i)\}_{i=1}^m\]- $s_i$: system prompt
- $u_i$: user input
- $o_i$: non-factual target output
-
Fine-tuning objective:
\[\min_{\Delta \theta} \sum_{i=1}^m -\log p(o_i \mid s_i, u_i; \theta + \Delta \theta)\]- $\theta$: original model parameters
- $\theta + \Delta \theta$: parameters of the hallucination-prone model
- The model is trained to reproduce non-factual outputs fluently and coherently.
⚖️ 3.2 Using Factually Weak LLM as a Penalty During Decoding
Base LLM Decoding
Auto-regressive decoding in standard LLMs:
\[p(x_t \mid x_{<t}; \theta) = \text{softmax}( \text{logit}_\theta(x_t \mid x_{<t}) )\]- $\text{logit}_\theta(·)$ is the next-token logits predicted by the original model $θ$.
Contrastive Adjustment
Subtract the hallucination-prone model’s log-probability to penalize non-factual outputs:
\[F_t = \beta \log p(x_t \mid x_{<t}; \theta) - \log p(x_t \mid x_{<t}; \theta + \Delta \theta)\]- $\beta \in (0, +\infty)$: a contrast strength hyperparameter
Final adjusted next-token distribution:
\[p(x_t \mid x_{<t}) = \text{softmax}(F_t)\]Adaptive Plausibility Constraint
Problem
Penalizing all outputs from the hallucinated model can hurt grammar, fluency, and common sense.
Solution
Only penalize likely tokens using a plausibility filter:
\[V_{\text{valid}} = \{x_t \in V : \text{logit}_\theta(x_t \mid x_{<t}) \geq \alpha \cdot \max_w \text{logit}_\theta(w)\}\]- $\alpha \in [0, 1]$: controls how restrictive the filter is
- Only consider tokens with probabilities larger than a proportion of the maximum probability assigned by the original model for contrast and decoding
- Tokens outside $V_{\text{valid}}$ are excluded by setting their logits to $-\infty$ before softmax
Experiments
The authors evaluate ICD on two types of hallucination benchmarks:
- Discrimination-based: Multiple-choice evaluations of truthfulness.
- Generation-based: Factual accuracy in open-ended biography generation.
⚙️ 4.1 Experimental Setup
Datasets & Metrics
- Discrimination-based:
- TruthfulQA
- Metrics:
- MC1: Does the model select the best answer?
- MC2: Does it assign higher probability mass to correct answers?
- MC3: Are correct answers consistently ranked above incorrect ones?
- Generation-based:
- FACTSCORE: Evaluates factual precision in biography generation.
- Metrics:
- % Response: Response rate
- # Facts: Average number of facts per response
- Factual Score: Precision of atomic facts based on ground-truth knowledge
- Example
Prompt: “Write a short biography of Ada Lovelace.”
Generated Text:
Ada Lovelace was a 19th-century mathematician known for her work on Charles Babbage’s Analytical Engine. She is often regarded as the first computer programmer.
Atomic Facts:
- Ada Lovelace was a 19th-century mathematician. ✅
- She worked on Charles Babbage’s Analytical Engine. ✅
- She is considered the first computer programmer. ✅ Score: 3/3 → 100% factual precision
Baselines
Compared ICD against:
- Greedy Decoding
- Inference Time Intervention (ITI): Adjusts hidden activations during inference
- DoLa: Contrastive decoding using early vs. late layers
- Vanilla Contrastive Decoding (CD): Contrasts output distributions from models of different sizes
Implementation Details
- Base model: Llama2-7B
- TruthfulQA:
- Fine-tuned on 10k hallucinated QA pairs from HaluEval
- Verified no data leakage with TruthfulQA
- FACTSCORE:
- Fine-tuned on 3.5k hallucinated biographies generated by ChatGPT
📈 4.2 Main Results
TruthfulQA – ICD Boosts Truthfulness
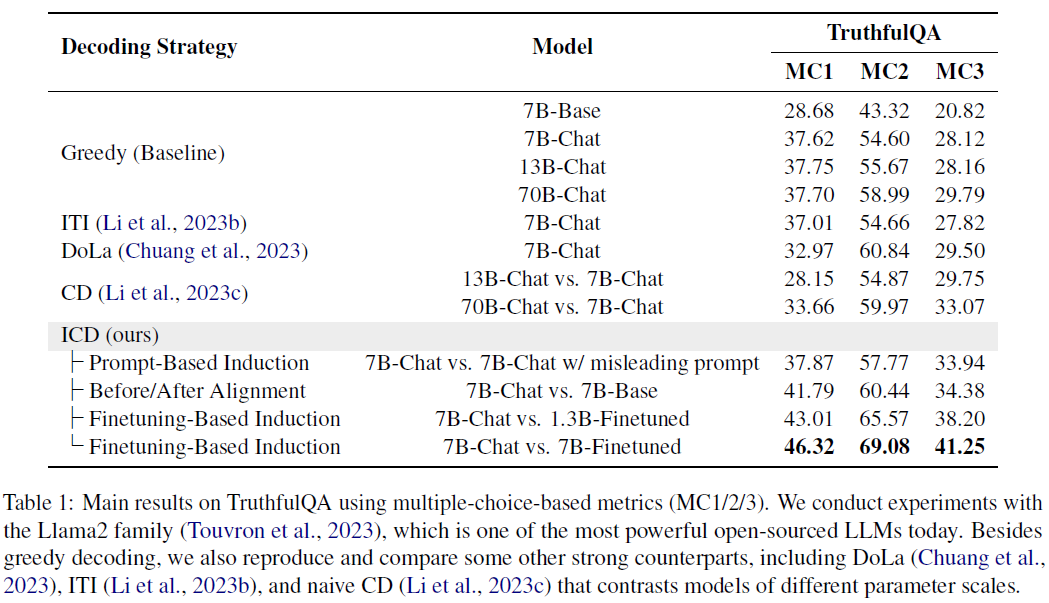
- Llama2-7B-Chat + ICD shows significant improvement over:
- Greedy decoding:
- +8.70 (MC1), +14.18 (MC2), +13.13 (MC3)
- Outperforms Llama2-70B, despite smaller size.
- Greedy decoding:
- ICD outperforms all other decoding baselines (ITI, DoLa, CD).
FACTSCORE – Reducing Open-ended Hallucinations
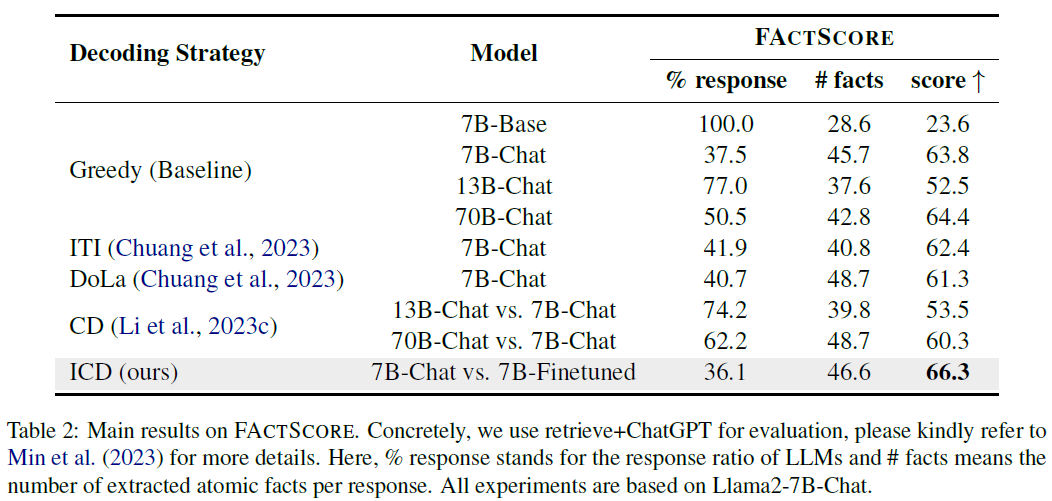
- ICD improves factual precision by +2.5 points over greedy decoding.
- Achieves 66.3 score, outperforming Llama2-70B (64.4).
- ICD maintains response rate and number of facts, unlike other methods which fail to improve the score.
Preserving General Capabilities
-
Evaluated ICD on MMLU, ARC, and AlpacaEval2.0:
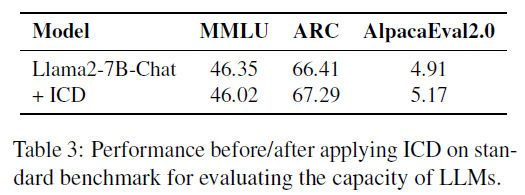
- No degradation in performance → ICD maintains original model capability.
-
GPT-4-based pairwise evaluations (Figure 3) on generated biographies:
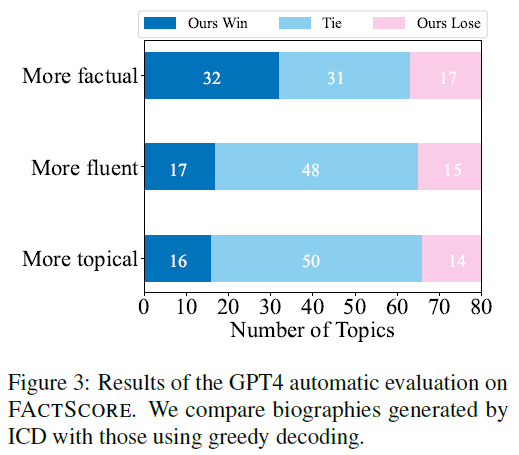
- ICD improves factuality
- Grammar and topicality remain unaffected
🧪 4.3 Further Exploration: Other Induction Strategies
Prompt-based Hallucination Induction
- Motivation: Avoid fine-tuning cost
- Approach: Use system prompts to manually induce hallucinations
- Example: Prompt LLMs to provide false answers
- Results:
- Some gains on TruthfulQA:
- From 37.62/54.60/28.12 to 37.87/57.55/33.94 (MC1/2/3)
- Not as effective as fine-tuning-based ICD
- Some gains on TruthfulQA:
Base vs. Chat Model Contrast
- Observation: Llama2-Chat is much more truthful than Llama2-Base due to SFT/RLHF
- New idea: Use base vs. chat model contrast (Before/After Alignment)
- Outcome:
- Better than naive CD
- Suggests alignment process introduces stronger truthfulness than scaling model size
🔍 4.4 More Analysis
Robustness to Task Formats
- Objective: Check whether the format of the hallucination-inducing training data affects ICD performance.
-
Result (Table 4):
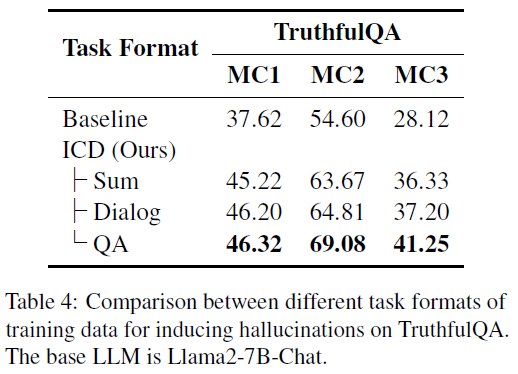
- All task formats improved performance.
- QA-format fine-tuning (matching TruthfulQA’s format) yielded the best gains.
- Conclusion: ICD generalizes across tasks, but task-aligned formats perform better.
Effectiveness Across Model Sizes
- Setup: Apply ICD to various Llama2 models using the same factually weak model (e.g., ShearedLLaMA-1.3B).
-
Result (Table 5):
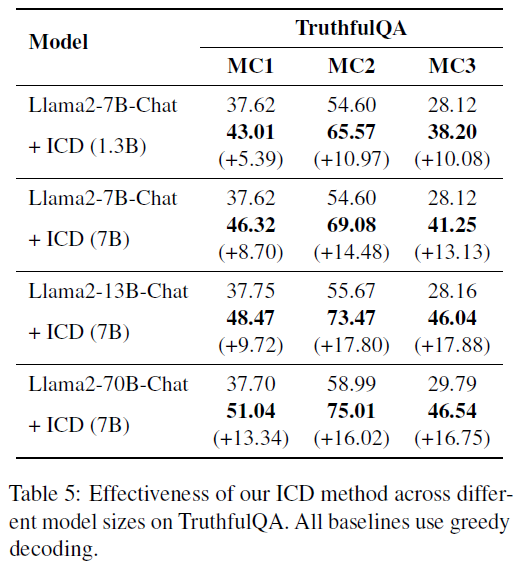
- Llama2-7B-Chat’s MC1 improved from 37.62 → 43.01.
- ICD remains effective across 7B, 13B, and 70B model sizes.
- Insight: ICD scales well and remains effective even when using smaller models as penalties.
Inference Speed & Efficiency
- Efficiency:
- Original and weak model can run in parallel, so no inference slowdown.
- Weak model can be smaller, which reduces GPU costs.
Real vs. Synthetic Data for Hallucination Induction
- Experiment: Compare ChatGPT-generated synthetic data vs. real hallucinations.
- Method:
- Ask Llama2-7B-Chat 1,000 open-domain Wikipedia-based questions.
- Human annotators filter out 294 real hallucinations.
-
Result (Table 6):
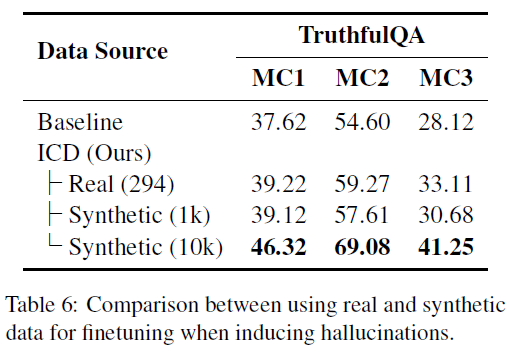
- 294 real samples > 1k synthetic samples in performance.
- 10k synthetic samples > 294 real samples, but gap is narrowing.
- Conclusion: Real hallucinations are more effective per sample, but larger synthetic datasets can close the gap.
Generalization to Other LLM Backbones
- Tested Models:
- Baichuan2
- Mistral
-
Result (Table 7):
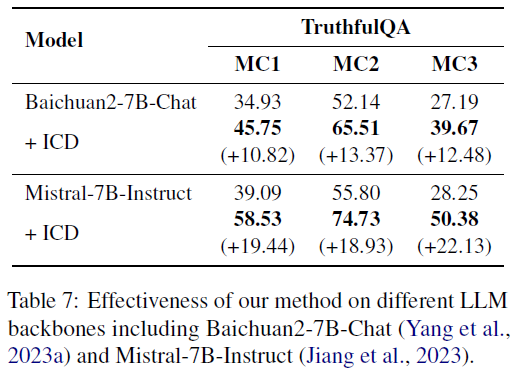
- ICD yields even stronger gains than with Llama2.
- These models are already stronger baselines, suggesting ICD scales with model quality.
- Insight: ICD is backbone-agnostic and leverages the strength of newer models.
⚠Why Not Just Fine-tune on Factual Data?
- Motivation: Can we skip ICD and just fine-tune on factual samples?
- Experiment:
- Fine-tune Llama2-7B-Chat on 3.5k factual biographies.
-
Result (Table 9):
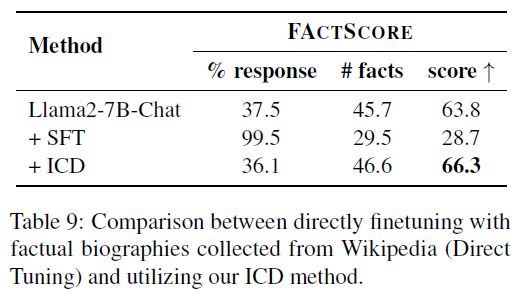
- Factuality drops dramatically: 63.8 → 28.7
- Response ratio spikes: 37.5 → 99.5
- Explanation:
- Likely due to behavior cloning: the model learns to answer everything, even beyond its knowledge.
- Aligns with prior findings (Schulman 2023, Yang et al. 2023c).
- Takeaway: Direct SFT with factual data is not reliable for hallucination mitigation.
Qualitative Analysis

- Source: Table 8 shows side-by-side generated biographies.
- Findings:
- Direct tuning:
- Introduces new hallucinations.
- Produces shorter, less helpful responses, degrading RLHF-learned style.
- ICD:
- Corrects factual errors, e.g., wrong birth year.
- Preserves helpfulness and fluency.
- Reverse contrast (hallucination induction):
- Produces grammatically fluent but factually wrong text.
- Confirms ICD’s ability to separate fluency from factuality.
- Direct tuning: