Paper Info.
- Title: Semantics-Adaptive Activation Intervention for LLMs via Dynamic Steering Vectors
- Authors: Weixuan Wang, Jingyuan Yang, Wei Peng
- Conference: ICLR 2025
- Code: https://github.com/weixuan-wang123/SADI
- Keywords: Activation Steering, Activation Intervention, Large Language Models (LLMs), LLM Safety
Introduction
🔍 Motivation & Problem Statement
Large Language Models (LLMs) like GPT and LLaMA have shown impressive capabilities across diverse tasks. However, ensuring these models behave in desired, aligned ways remains a significant challenge.
Limitations of Existing Alignment Methods:
- Supervised fine-tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) are powerful but:
- Require large annotated datasets.
- Struggle with hallucination prevention.
- May still fail to produce intended behaviors.
- Prompt engineering can guide outputs but often lacks reliability and flexibility.
Rise of Activation Engineering
- A newer family of techniques, activation engineering, tries to steer LLM behavior by modifying internal activations (e.g., hidden states or attention heads) without re-training the model.
- It works by injecting steering vectors into the forward pass, altering model behavior at runtime.
- However, existing approaches use fixed steering vectors, which cannot adapt to the semantic diversity of different inputs.
Why Fixed Steering Vectors Fail:
- Semantic misalignment between the static vector and the actual input can degrade performance.
- This gap is especially harmful in inference-time applications with diverse inputs.
💡 Proposed Solution: SADI (Semantics-Adaptive Dynamic Intervention)
To overcome the limitations of fixed steering, the authors propose SADI, a method that creates a dynamically generated steering vector for each input during inference.
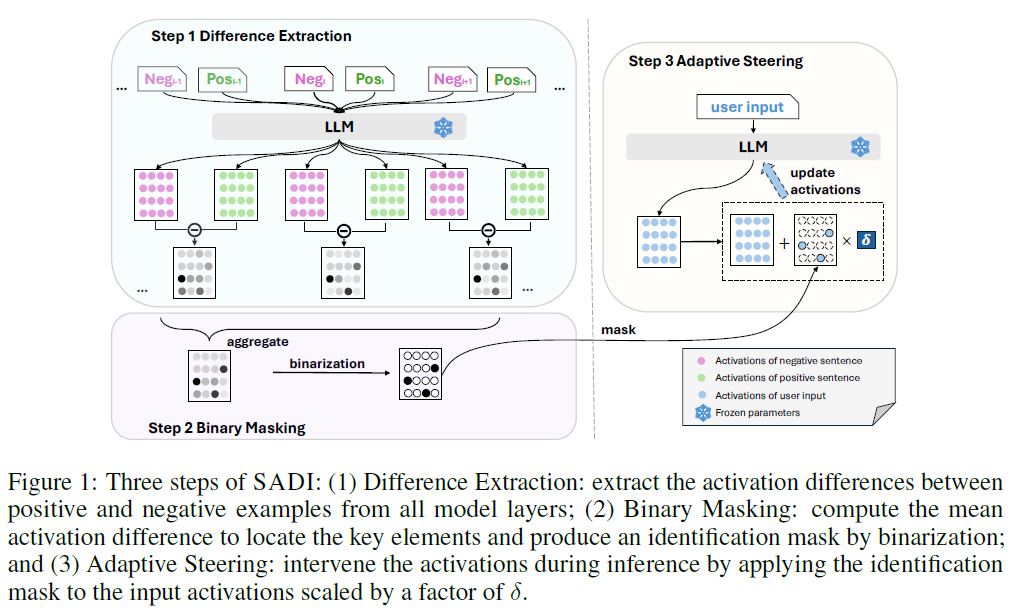
Key Ideas and Mechanism:
- Contrastive pairs (e.g., positive vs. negative examples) are used to measure activation differences and generate a binary mask that highlights critical components in the model (e.g., neurons, attention heads).
- During inference, element-wise scaling is applied to those components to dynamically adjust model behavior in line with the semantic content of the input.
- Variants of the method:
- SADI-HIDDEN: modifies hidden states.
- SADI-HEAD: modifies attention heads.
- SADI-NEURON: modifies feed-forward neurons.
🧪 Experimental Overview
SADI is tested on:
- 4 LLMs: LLAMA2-7B-CHAT, BLOOMZ-7B, MISTRAL-7B, FALCON-7B-INSTRUCT
- 11 Benchmarks across both:
- Multiple-choice tasks (COPA, NLI, SST2, MMLU, BoolQ, etc.)
- Open-ended generation (TriviaQA, ToxiGen, TruthfulQA)
Key Results:
- SADI significantly outperforms existing activation intervention methods.
- SADI-HEAD in particular shows strong and consistent improvements across tasks.
- Demonstrates generalizability:
- Works across model sizes.
- Effective in few-shot and multilingual settings.
- Cost-effective:
- Requires only ~150 examples for vector construction.
- No training is needed (i.e., only inference-time modifications).
✅ Summary of Contributions
- Novel Approach: SADI provides a training-free, inference-time steering method tailored to input semantics.
- Strong Performance: Achieves up to +14.69 accuracy improvement over baselines across many tasks and models.
- Broad Applicability: Scales well across languages, model sizes, and low-resource settings with minimal data.
Related Work
Background: Activation Engineering
Activation engineering has recently emerged as a cost-effective and efficient technique for modifying the behavior of large language models (LLMs) at inference time without retraining. The core idea is to alter the model’s internal activations during decoding based on activation differences derived from contrastive examples (e.g., toxic vs. non-toxic prompts).
Key Approaches and Applications:
- Truthfulness improvement: Some works steer activations along the vector difference between truthful and untruthful outputs, helping the model generate more factually accurate content (Li et al., 2023b (ITI); Chen et al., 2024).
- Toxicity mitigation: Others use discrepancies in contextual examples to reduce harmful or toxic outputs (Liu et al., 2023).
- General-purpose behavior shifts: Techniques like Turner et al. (2023) and Rimsky et al. (2023) show that intermediate activation differences (e.g., between negative vs. positive sentiment prompts) can construct steering vectors to induce desired changes in tone or behavior.
- These interventions are often applied to residual streams or hidden states, avoiding the need for full model retraining.
Theoretical Foundation: Linear Representation Hypothesis
The paper is grounded in the linear representation hypothesis (Park et al., 2024; Turner et al., 2023), which asserts that:
- High-level features (e.g., sentiment, truthfulness, toxicity) are encoded as linear directions in the model’s representation space.
- Thus, one can steer model behavior by adding a direction-specific steering vector to the current representation without affecting unrelated features.
Key Insight: To make effective modifications, the steering should preserve and align with the semantic direction of the input. This ensures the output remains relevant and coherent.
Limitation of Existing Methods
- Existing methods rely on fixed steering vectors derived from pre-collected contrastive pairs.
- These vectors do not adapt to the semantics of the current input during inference.
- This is problematic because:
- Activation patterns can vary widely across inputs, even for the same task (Wang et al., 2024a;b).
- Applying a static vector may steer the model in a direction that’s misaligned with the current context, hurting performance or causing undesired outputs.
Need for Adaptivity
The discussion culminates in identifying a critical gap: the lack of semantic adaptivity in existing activation interventions.
- Dynamic steering that adjusts based on each input’s semantics is essential for more precise, context-sensitive interventions.
- This gap motivates the Semantics-Adaptive Dynamic Intervention (SADI) approach proposed in the paper.
Semantics-Adaptive Dynamic Intervention (SADI)
3.1 🔍 Overview of SADI
SADI consists of the following three key steps (see Fig. 1 above):
- Difference Extraction: Compute activation differences between positive and negative outputs across all layers.
- Binary Masking: Create a binary mask that highlights only the most influential activation components.
- Adaptive Steering: At inference time, apply the mask and scale the activations of a given input in a direction aligned with its semantics.
This process allows SADI to intervene precisely without retraining the model.
3.2 🔬 Difference Extraction
- Objective: Identify internal activation differences that distinguish positive (e.g., correct) from negative (e.g., incorrect) outputs.
- Setup:
- Model: $P = {P_l \mid 0 \leq l < L}$ for $L$ layers.
- Dataset: $T = {(x_i, y_i^{\text{pos}}, y_i^{\text{neg}})}_{i=1}^N$
- Activation Collection:
- For each instance, concatenate input $x_i$ with either $y_i^{\text{pos}}$ or $y_i^{\text{neg}}$, and extract activations at the last token from each layer:
- $A_i^{\text{pos}, (l)} = P_l(x_i \,|\, y_i^{\text{pos}})$
- $A_i^{\text{neg},(l)} = P_l(x_i \,|\, y_i^{\text{neg}})$
- For each instance, concatenate input $x_i$ with either $y_i^{\text{pos}}$ or $y_i^{\text{neg}}$, and extract activations at the last token from each layer:
- Compute Activation Differences:
These differences $D_i^{(l)}$ indicate which activations are critical for model behavior.
3.3 🎯 Binary Masking
- Aggregate Differences:
- Here, $D \in \mathbb{R}^{L \times d_m}$ where $d_m$ is the dimensionality of model elements (e.g., neurons, hidden states).
- Binary Mask Generation:
- Retain only the top-K highest-magnitude elements:
- $E_K$: indices of the top-K elements with largest mean differences.
This mask focuses the intervention on the most impactful components, minimizing disruption.
3.4 ⚙️ Adaptive Steering
- Goal: Intervene in a way that respects the semantic direction of each specific input.
- Problem with Previous Work: Prior methods modify all activations uniformly, potentially misaligning the output or harming unrelated behaviors.
- SADI’s Approach:
-
For a given input $q$, extract activations $A_q^{(l)}$ from each layer and concatenate:
\[A_q = \text{Concat}(A_q^{(0)}, A_q^{(1)}, \dots, A_q^{(L-1)})\] -
Apply the binary mask and steer the activation using:
\[A'_q = A_q + \delta (A_q \odot M)\]- $\odot$: element-wise multiplication
- $\delta$: scalar hyperparameter controlling intervention strength
-
- Benefits:
- Steering vector is input-aware and dynamically aligned with semantic direction.
- Reduces undesired side effects by limiting intervention to top-K components.
- Even though $\delta$ is fixed, $A_q$ is input-specific, so the direction and affected elements of the update are input-dependent.
🛠️ Hyperparameters
- $K \in \mathbb{N}^+$: Number of top elements used in masking.
- $\delta \in \mathbb{R}^+$: Scaling factor for the steering adjustment.
- These are selected via hyperparameter sweeps (see Section 4.3).
SADI’s Algorithm

My comments
A more adaptive variant could define:
- $\delta(q)$ as a function of input (e.g., attention entropy, token gradients),
- Or a layer-wise or token-specific scaling factor.
Experiments
4.1 🔧 Experiment Settings
Tasks & Metrics
- Multiple-choice tasks:
- Datasets: COPA, StoryCloze, NLI, MMLU, SST2, SST5, BoolQ, Winogrande
- Metric: Accuracy
- Open-ended generation tasks:
- Datasets: TriviaQA, TruthfulQA, ToxiGen
- Metrics:
- Exact Match (EM) for TriviaQA
- Multiple-choice accuracy + model-based truthfulness/informativeness for TruthfulQA
- Toxicity score via HATEBERT for ToxiGen
Contrastive Pair Construction
- Multiple-choice: Combine ‘prompt + correct answer’ (positive), ‘prompt + random wrong answer’ (negative)
- TriviaQA: Use empty string as a negative answer
- TruthfulQA: Use multiple-choice format
- ToxiGen: Negative prompts come from RealToxicityPrompts with toxicity score > 0.955
Models Used
- Main baseline: LLAMA2-7B-CHAT
- Others for generalization:
- BLOOMZ-7B, MISTRAL-7B, FALCON-7B-INSTRUCT
- Also tested on BLOOMZ-560M, 1B, 3B to study scalability
4.2 🔁 Compared Methods
Baselines:
- Supervised Fine-Tuning (SFT):
- Fully fine-tunes model parameters
- High accuracy, but expensive and data-dependent
- Inference-Time Intervention (ITI):
- Selects top attention heads via contrastive pairs
- Tunes head set and strength of intervention
- Contrastive Activation Addition (CAA):
- Applies fixed steering vector based on average activation differences
SADI Variants:
- SADI-HIDDEN: Applies to key hidden states
- It identifies specific dimensions of the token-wise hidden vectors (shape:
[seq_len, hidden_dim]) that show strong activation difference between contrastive pairs.
- It identifies specific dimensions of the token-wise hidden vectors (shape:
- SADI-HEAD: Applies to attention heads
- Inside the multi-head self-attention mechanism of each transformer block.
- SADI-NEURON: Applies to FFN neurons after non-linearities
- In the feed-forward network (FFN) sub-block of each transformer layer.
4.3 📊 Experimental Results
Multiple-Choice Task Results (Table 1)
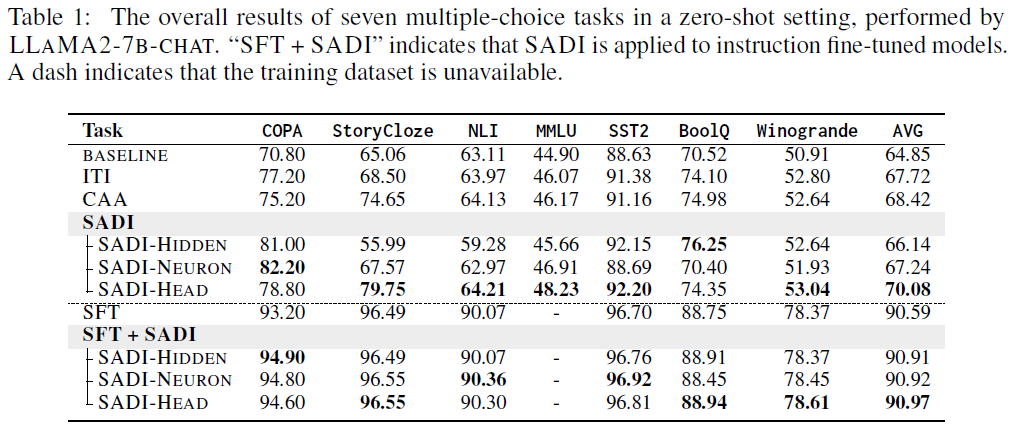
- SADI outperforms all inference-time baselines (CAA, ITI) across tasks.
- Compared to SFT:
- SFT performs best with ample training data (e.g., COPA, StoryCloze)
- SADI shines in low-data scenarios (e.g., MMLU)
- StoryCloze:
- SADI achieves a +14.69 gain over BASELINE
- Outperforms ITI by +11.25, CAA by +5.10
Breakdown by SADI Variant
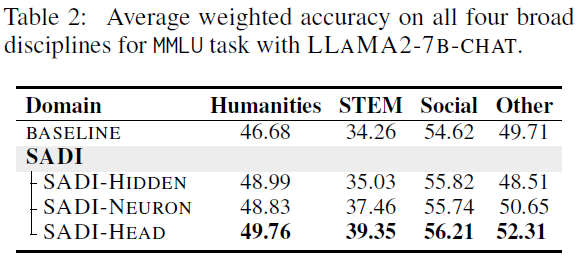
- SADI-HEAD is the most effective:
- Highest accuracy improvements on average (+5.23)
- Best in most tasks, e.g., MMLU-STEM (+5.09), COPA, BoolQ
- SADI-HIDDEN / NEURON:
- Strong in specific tasks (e.g., BoolQ: 76.25, COPA: 82.20)
- But slightly worse in some tasks like NLI
Open-Ended Generation Results (Table 3)
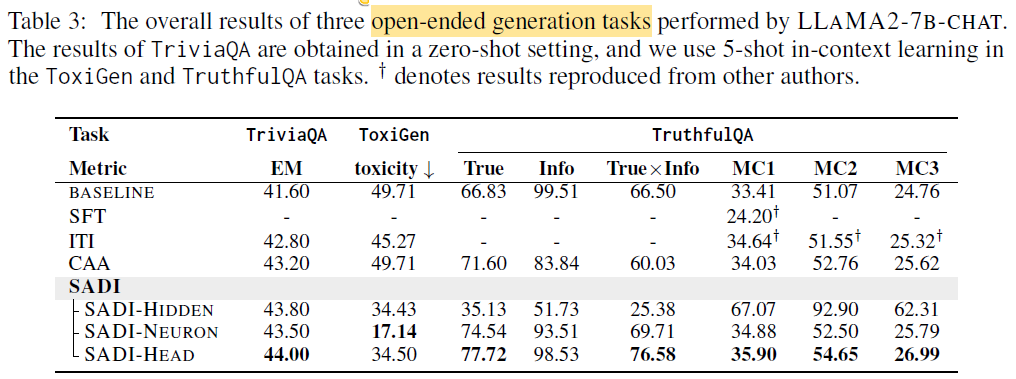
- SADI improves over BASELINE across most generation tasks
- TriviaQA → zero-shot setting, ToxiGen/TruthfulQA → 5-shot in-context learning
- TruthfulQA (True×Info metric):
- SADI-HEAD achieves up to +10.08 improvement
- SADI-HIDDEN underperforms for generation, better for multiple-choice
- Suggests sensitivity of hidden states to task format
4.4 🔍 Component Analysis & Ablation (Table 4)
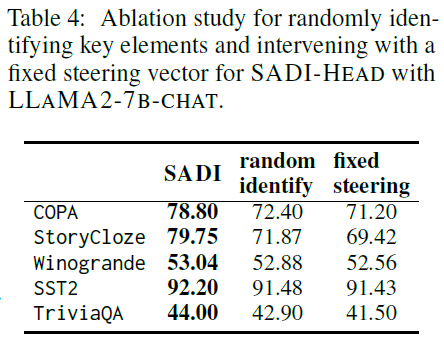
Binary Masking (Step 2)
- Random mask: Assigns random top-K elements
- Leads to significant performance drop, e.g., -7.88 on StoryCloze
- Shows that selectively identifying important elements is crucial
Adaptive Steering (Step 3)
- Compared:
- SADI (semantic-adaptive): $A_q’ = A_q + \delta (A_q \odot M)$
- Fixed steering: $A_q’ = A_q + \delta (D \odot M)$
- Here, $D$ is a fixed direction from contrastive pairs
- Results:
- Fixed steering leads to large performance drops
- Highlights the importance of aligning steering direction with input semantics
⚙️ Hyperparameter Sensitivity (Figure 2)
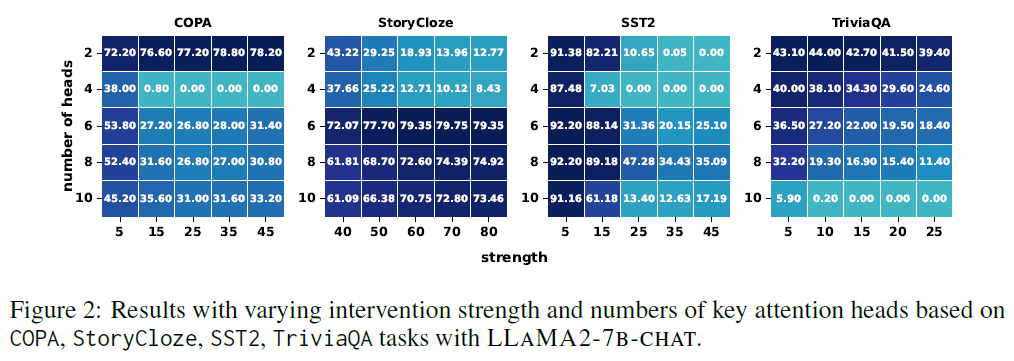
- Hyperparameters:
- $K$: Number of elements selected for intervention
- $\delta$: Strength of intervention
- Optimal values vary by task
- Suggests the need for validation-based tuning
- Trade-off:
- Too many heads or too strong $\delta$ can hurt performance
My comments
Potential Limitations / Assumptions
- Task-Specific Setup:
- For each task, a separate mask is built using that task’s data.
- So the intervention is not cross-task transferable unless retrained.
- It’s not a “general-purpose” steering vector usable on unseen tasks.
- Small-scale supervision:
- Even though it avoids full fine-tuning, it still uses task labels during contrastive pair construction.
- So the claim of “no training” is true in terms of model parameters, but the method does require access to labeled data at inference time.
Discussion
This section evaluates the generalizability and robustness of SADI across various axes:
- Different LLM backbones
- Model sizes
- Few-shot learning settings
- Multilingual scenarios
5.1 Generalizability Across Multiple LLMs
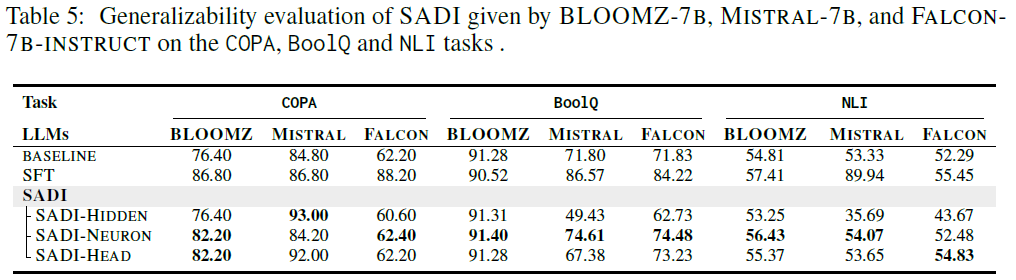
- Objective: Test whether SADI’s dynamic intervention works across different model architectures.
- Models tested: BLOOMZ-7B, MISTRAL-7B, FALCON-7B-INSTRUCT
- Tasks: COPA, BoolQ, NLI
- Findings:
- SADI improves performance across all models, confirming its architecture-agnostic utility.
- However, the best-performing SADI configuration varies by model.
- For example, SADI-NEURON with BLOOMZ-7B yields the highest gains across all three tasks.
- This implies that different LLMs have different “functionally sensitive” components, reinforcing the need for flexible intervention targets.
5.2 Generalizability Across Model Sizes
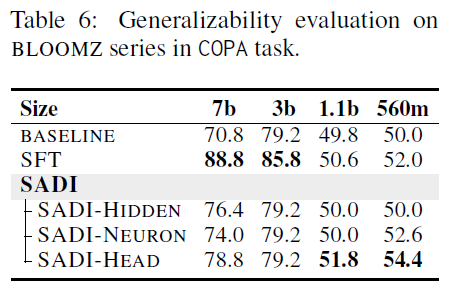
- Objective: Evaluate SADI’s performance on smaller-scale models, where capacity is more limited.
- Models: BLOOMZ-560M, BLOOMZ-1B, BLOOMZ-3B (subset of BLOOMZ family)
- Key Results (Table 6):
- SADI maintains its performance improvement even as model size decreases.
- Notably, SADI outperforms SFT in smaller models:
- +1.2 accuracy gain for BLOOMZ-1B
- +2.4 accuracy gain for BLOOMZ-560M
- Conclusion:
- SADI is especially effective for resource-constrained models, where fine-tuning is less feasible or effective.
5.3 Generalizability in Few-Shot Settings

- Objective: Examine how SADI performs when few-shot prompts (rather than zero-shot) are provided during inference.
- Tasks: SST5, Winogrande, TruthfulQA
- Method: Compare BASELINE and SADI-HEAD under zero-shot vs. few-shot conditions (Table 7).
- Findings:
- SADI-HEAD improves performance in both zero-shot and few-shot cases.
- However, the performance gains are smaller in few-shot settings.
- Reason: Few-shot prompts already give the model a strong learning signal, reducing the additional value of activation intervention.
- Conclusion:
- SADI is still beneficial, but its relative impact is diminished when few-shot examples are already informative.
5.4 Generalizability in Multilingual Scenarios
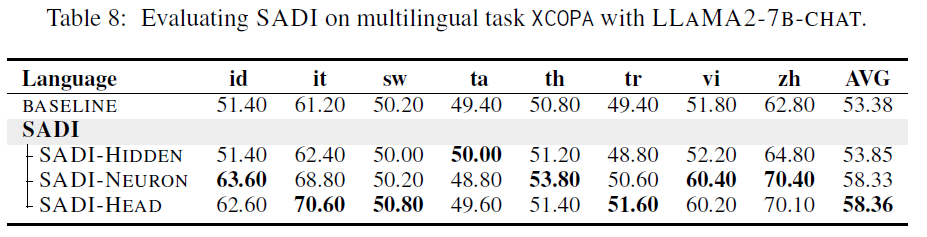
- Objective: Test whether SADI can handle non-English language inputs.
- Dataset: XCOPA (multilingual version of COPA)
- Languages: 8 total (Indonesian (id), Italian (it), Swahili (sw), Tamil (ta), Thai (th), Turkish (tr), Vietnamese (vi), Chinese (zh))
- Results (Table 8):
- SADI consistently improves performance across all languages.
- Degree of improvement varies:
- Highest gain: Indonesian
- Lowest gain: Swahili
- Conclusion:
- SADI is capable of multi-lingual & cross-lingual activation intervention, suggesting the underlying activation differences generalize across language boundaries.
- Further component-level analysis is available in Appendices A.3 and A.4.
Analysis
This section investigates:
- Where in the model activation differences are concentrated.
- How SADI compares to supervised fine-tuning (SFT) under varying data availability.
6.1 Characteristics of Activation Differences
Activation differences are not evenly distributed across the model’s layers or components.
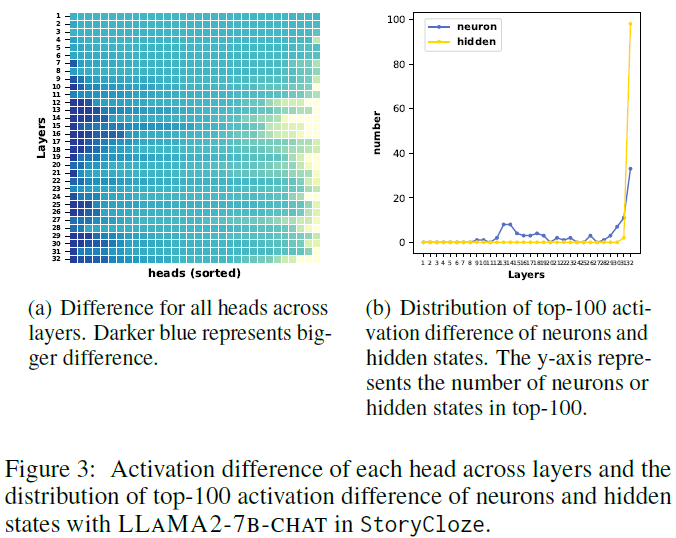
Attention Heads (Figure 3a):
- In the StoryCloze task, the middle to later transformer layers show the strongest activation differences between contrastive prompts.
- This suggests information processing is concentrated in those layers.
Neurons & Hidden States (Figure 3b):
- Differences in FFN neurons and hidden state activations are even more strongly localized to the final layer.
- This is consistent with their role in semantic representation and output prediction.
Theoretical Alignment:
- These patterns support the functional segregation hypothesis (Zhao et al., 2024):
- Middle layers → responsible for reasoning.
- Later layers → responsible for generation.
- Therefore, SADI interventions on attention heads likely affect both reasoning and language generation, contributing to its robust performance across task types.
6.2 SADI vs. SFT with Varying Data
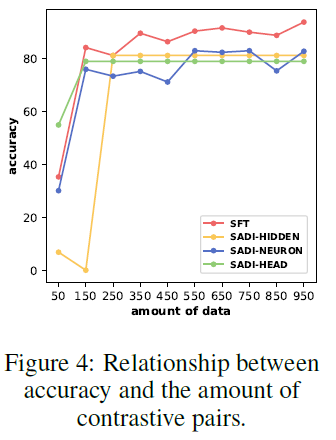
Experiment:
- Comparison of SADI and SFT on the COPA task with varying amounts of data (Figure 4).
SFT Behavior:
- Performance increases as the number of training examples increases (as expected).
- But SFT requires a large number of labeled examples to reach high accuracy.
SADI Behavior:
- SADI achieves strong performance even with as few as 150 contrastive pairs.
- These are only used to compute the identification mask (i.e., no parameter updates are required).
- This confirms SADI’s efficiency and suitability for low-resource settings.
Conclusion
- SADI is introduced as a training-free, inference-time method for steering LLM behavior based on semantic context.
- It works by identifying and modulating critical activations (attention heads, neurons, hidden states).
- Extensive experiments show:
- Generalization across tasks, models, and languages.
- Clear improvement over both baseline and previous intervention techniques.
- The paper contributes to the growing field of activation engineering, and opens the door to more controllable and interpretable LLMs in the future.