Paper Info.
- Title: DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
- Authors: Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, Pengcheng He
- Conference: ICLR 2024
- Code: https://github.com/voidism/DoLa.git
- Keywords: Large Language Models (LLMs), LLM Safety, Hallucination, Factuality, Decoding, Text Generation
Introduction
🧠 Motivation: The Hallucination Problem in LLMs
- Large language models (LLMs) have shown impressive capabilities in NLP tasks, especially as they are scaled up.
- However, they often hallucinate (i.e., generating text that deviates from factual knowledge seen during pre-training).
- This is a major obstacle in deploying LLMs in high-stakes domains (e.g., healthcare, law) where factual correctness is crucial.
⚠️ Why Do Hallucinations Occur?
- The standard training objective (i.e., maximum likelihood estimation (MLE)) minimizes forward KL divergence, which makes the model mass-seeking.
- As a result, the model may assign non-zero probability to plausible but incorrect statements, instead of strictly factual ones.
- Empirically, such models tend to learn surface linguistic patterns rather than grounding outputs in real-world knowledge.
🔍 Key Insight: Layer-Wise Knowledge in Transformers
- Prior work shows that different layers encode different types of information:
- Lower layers: syntactic or structural cues (e.g., part-of-speech).
- Higher layers: semantic content or factual knowledge.
- Research shows that:
- “Knowledge neurons” cluster in upper layers (e.g., BERT).
- Factual knowledge can be edited in specific layers of autoregressive models.
🚀 Proposed Solution: DoLa
- The authors propose a decoding-only method called DoLa (Decoding by Contrasting Layers).
- Core idea: At each step in generation, compute the difference in output logits between a higher layer and a lower layer.
- This contrast amplifies factual information encoded in higher layers.
- It also downplays syntactically plausible but factually wrong outputs that persist across all layers.
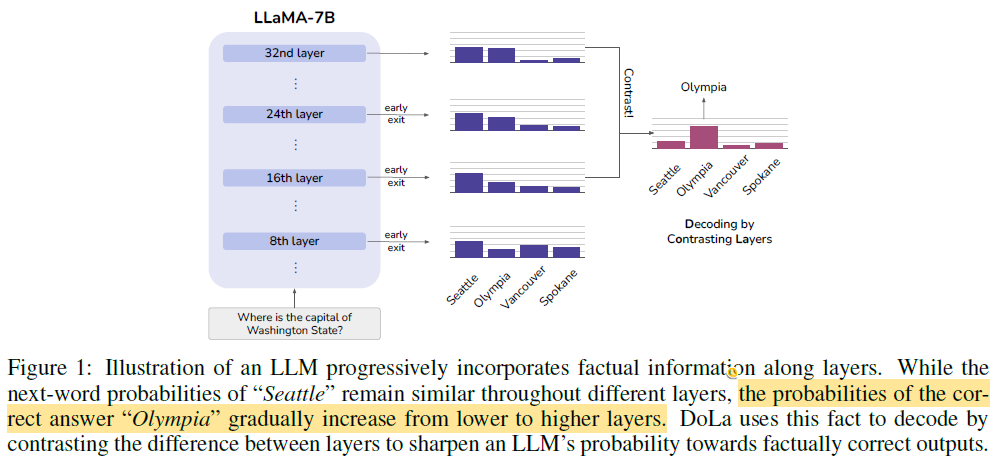
Example: In a multiple-choice setting, “Seattle” may score high across layers (due to syntax), but the true factual answer “Olympia” becomes more prominent only in higher layers. DoLa helps surface such correct answers.
✅ Advantages of DoLa
- No need for external knowledge retrieval or fine-tuning.
- Efficient: only minor latency overhead during decoding.
- Applicable to decoder-only LLMs (e.g., LLaMA).
📊 Experimental Results
- Truthfulness improvement is demonstrated on:
- TruthfulQA and FACTOR benchmarks (factual QA).
- StrategyQA and GSM8K (chain-of-thought reasoning).
- Chatbot evaluations with GPT-4, showing significantly more factual and informative outputs under DoLa.
Method
🔧 Overview of Standard Decoding in LLMs
Typical transformer-based LLMs consist of:
- An embedding layer
- $N$ stacked transformer layers
- A final affine projection head $\phi(\cdot)$
Given a token sequence ${x_1, x_2, \dots, x_{t-1}}$, the model predicts $x_t$ using:
\[p(x_t \mid x_{<t}) = \text{softmax}(\phi(h_t^{(N)}))\]- where $h_t^{(N)}$ is the hidden state from the final (mature) layer at time $t$.
🚀 DOLA: Core Idea
Instead of only using the final layer’s logits, DOLA (Decoding by Contrasting Layers) proposes:
- Selecting an early layer (premature layer) dynamically
- Computing two output distributions:
- $q_N(x_t) = \text{softmax}(\phi(h_t^{(N)}))$
- $q_M(x_t) = \text{softmax}(\phi(h_t^{(M)}))$
-
Contrasting them via:
\[\hat{p}(x_t \mid x_{<t}) = \text{softmax}(F(q_N(x_t), q_M(x_t)))\]- where the operator $F(·, ·)$ is used to contrast between the output distributions from the premature layer and the mature layer by computing the log-domain difference between two distributions.
🧠 2.1 Factual Knowledge Evolves Across Layers
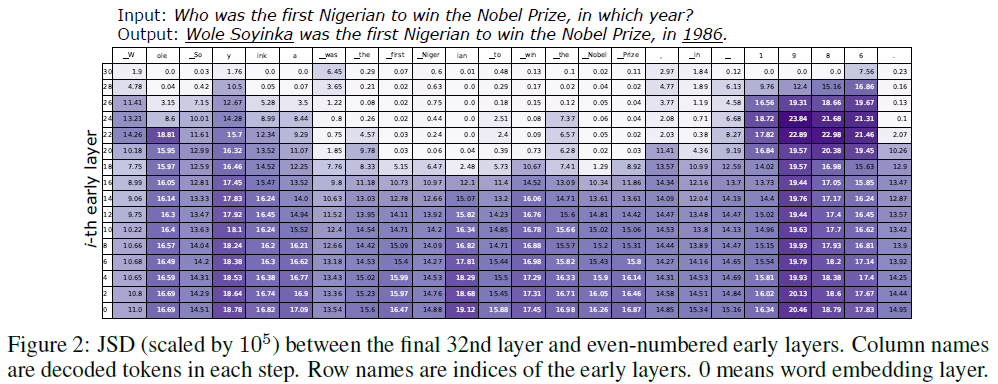
- The authors compute Jensen-Shannon Divergence (JSD) between early-layer and final-layer distributions.
- Two patterns observed:
- Pattern 1: For factual tokens (e.g., names, dates), JSD remains high in upper layers, suggesting that factual knowledge is introduced later.
- Pattern 2: For function words or copied tokens, JSD drops early, indicating early-layer stabilization.
Conclusion: Factual predictions evolve in higher layers → contrast reveals factual knowledge.
🔄 2.2 Dynamic Premature Layer Selection
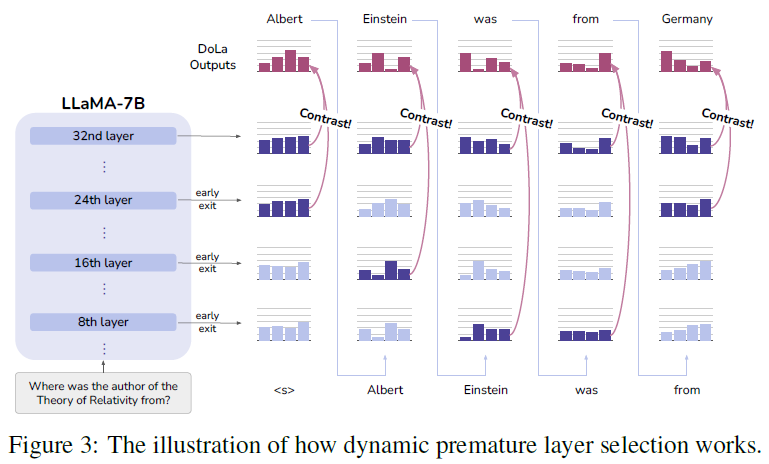
To find the most informative contrast point:
- Select premature layer $M$ that maximizes JSD with the final layer:
- $J \subset {0, …, N-1}$ is a predefined set of candidate early layers (e.g., grouped into buckets).
- This allows DOLA to adapt to token difficulty dynamically at each step.
- Easy tokens → lower JSD → earlier premature layer
- Hard/factual tokens → higher JSD → later premature layer
DoLa-static vs. Dynamic
- DoLa-static: Premature layer is fixed via validation search (inefficient and less generalizable).
- Dynamic strategy: Requires no exhaustive tuning and is more robust across datasets.
⚖️ 2.3 Contrasting the Predictions
Once $q_N$ and $q_M$ are selected:
- Use log-ratio contrast to enhance mature layer preferences:
- This highlights mature-layer-favored tokens and suppresses early-layer biases.
Adaptive Plausibility Constraint (APC)
To avoid unstable outputs:
- Define vocabulary subset:
- Ensures contrast is only applied to plausible tokens, preventing:
- False positives: Low-probability junk tokens being boosted
- False negatives: Stable, correct tokens being suppressed
🔁 Repetition Penalty
- To reduce output repetition (e.g., in long CoT reasoning), DOLA applies a repetition penalty of $\theta = 1.2$ during decoding.
- Based on Keskar et al. (2019); empirical effects are discussed in the appendix.
✅ Key Benefits of DOLA
- Amplifies factual signals from higher layers
- Adapts to token difficulty via JSD-based dynamic layer selection
- Requires no fine-tuning or external knowledge
- Introduces minimal computational overhead during inference
Experiments
3.1 Experimental Setup
Datasets
Experiments span multiple-choice and open-ended generation tasks:
- Multiple-choice:
- TruthfulQA (short factual answers)
- FACTOR (long-paragraph factual tasks; News/Wiki)
- Open-ended generation:
- TruthfulQA (scored by GPT-3 on truthfulness/informativeness)
- StrategyQA (requires multi-hop reasoning)
- GSM8K (math word problems)
- Vicuna QA (GPT-4-evaluated instruction-following)
Models and Baselines
- Models: LLaMA-7B, 13B, 33B, 65B
- Baselines:
- Original Decoding: Greedy/sampling
- Contrastive Decoding (CD): Uses smaller LLaMA-7B as “amateur”, compared to larger “expert”
- Inference Time Intervention (ITI): LLaMA-7B + linear classifier trained on TruthfulQA
DoLa contrasts internal layers rather than external models (CD), keeping the evaluation clean.
Implementation Details
- Adaptive plausibility constraint (APC): α = 0.1
- Repetition penalty: θ = 1.2
- Layer bucket candidates:
- 7B (32-layer): [0, 16), [16, 32)
- 13B (40-layer): [0, 20), [20, 40)
- 33B (60-layer): [0, 20), [20, 40), [40, 60)
- 65B (80-layer): [0, 20), [20, 40), [40, 60), [60, 80)
- Note: They use validation set to select the best bucket.
- Validation:
- Two-fold for TruthfulQA/FACTOR
- GSM8K subset used for StrategyQA/Vicuna QA
3.2 Multiple Choice Results
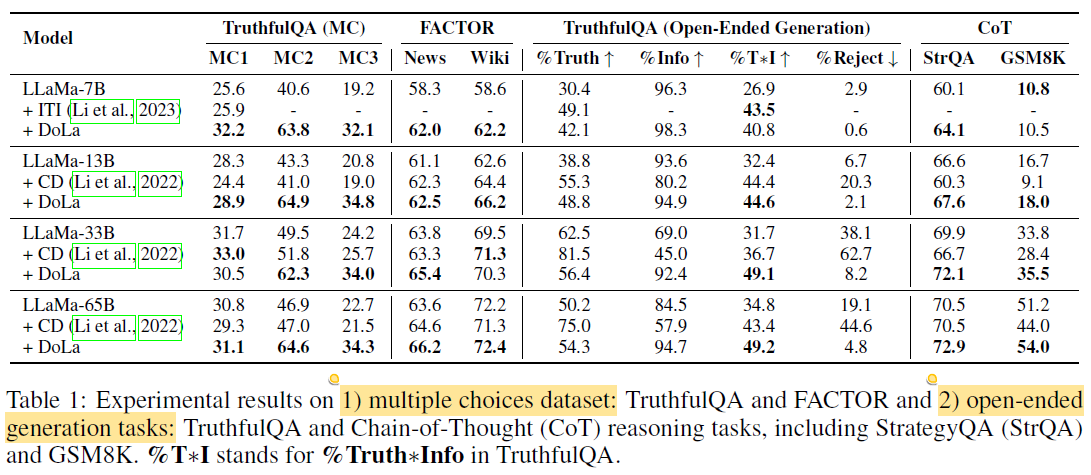
TruthfulQA (Short-Answer Factuality)
- Metrics: MC1 (hard), MC2/MC3 (softer, averaged scores)
- Findings:
- DoLa improves all models significantly vs. CD and ITI.
- Exception: LLaMA-33B on MC1 (sensitive to fluctuations).
- Validated layer choices consistently select higher layers, e.g.,:
- 7B: [16, 32), 13B: [20, 40), 33B: [40, 60), 65B: [60, 80)
FACTOR (Long-Paragraph Factuality)
- Task: Choose correct completion from four options
- Validation folds: News and Wiki subsets
- Results:
- DoLa outperforms baselines by 2–4%
- Lower layer contrasts are preferred (e.g., [0, 20)), opposite to TruthfulQA.
- Reason: Longer outputs have more low-level tokens; lower layers better preserve general context.
3.3 Open-Ended Text Generation
TruthfulQA (GPT-3 Ratings)
- Metrics:
- %Truthful
- %Informative
- %Reject (“I have no comment”)
- %Truth × %Info
- Results:
- DoLa improves truthfulness while maintaining informativeness (>90%)
- %Reject stays <10%
- CD fails: Though it boosts truthfulness, it overuses rejections (e.g., 60% for LLaMA-33B), lowering the final score.
- Explanation: 33B model’s stronger instruction-following (e.g., prompt says “refuse if unsure”) → CD generates more refusals than necessary.
Chain-of-Thought Reasoning
StrategyQA
- Requires multi-hop reasoning
- DoLa improves accuracy by 1–4%
- CD performs worse (reasoning likely degraded by contrasting with a smaller 7B model)
GSM8K
- Involves factual + arithmetic reasoning
- DoLa improves accuracy by ~2% on most models (except 7B)
- Shows DoLa benefits extend to arithmetic-heavy reasoning
✅ Lower-layer contrast was consistently selected for CoT tasks: [0, 16) or [0, 20)
Instruction-Following: Vicuna QA (GPT-4 Rated)
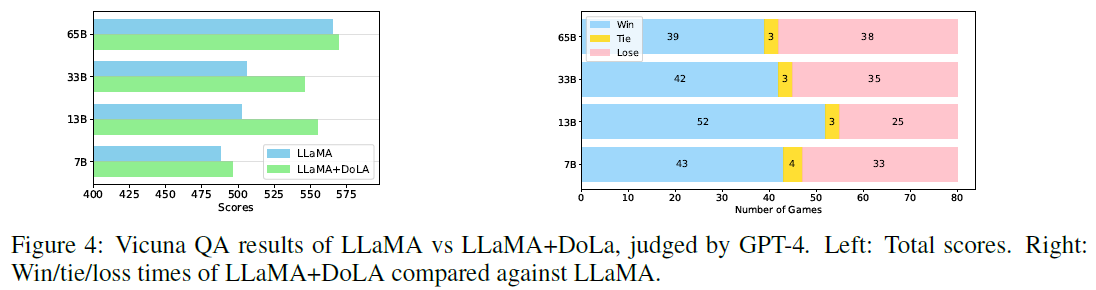
- GPT-4 scores chatbots in pairwise comparisons
- DoLa uses lower layers, following GSM8K results
- Results (Figure 4): DoLa outperforms baselines significantly on 13B and 33B models
- Confirms DoLa’s robustness across open-ended, dialogue-style tasks
Analysis
🔍 4.1 Premature Layer Selection Strategy
Goal:
Evaluate and compare different strategies for selecting the premature layer used in contrastive decoding:
- DoLa-static: Uses a fixed layer for contrast throughout decoding
- DoLa (default): Uses dynamic selection based on Jensen-Shannon Divergence (JSD) per decoding step
Experimental Findings (GSM8K Validation Sets):
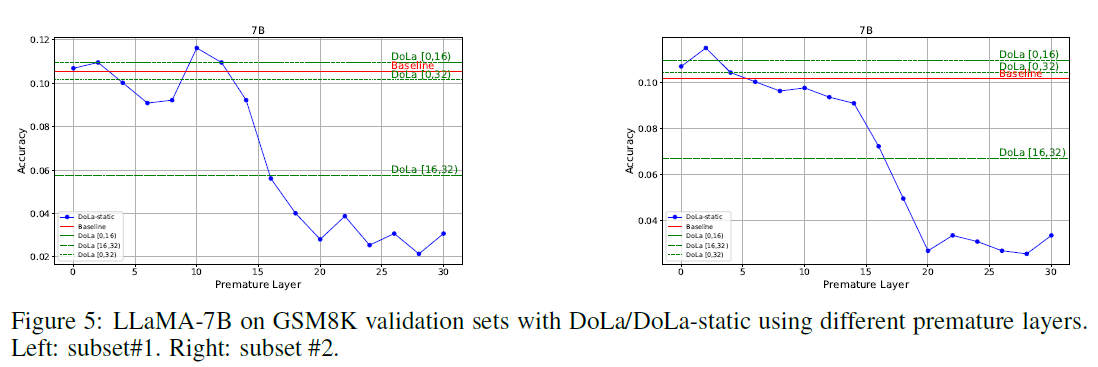
- DoLa-static can sometimes outperform DoLa, especially when the “optimal” fixed layer is well chosen (e.g., 10th layer in subset #1).
- However, this optimal layer is highly sensitive to the dataset:
- In subset #1: 10th layer is best
- In subset #2: 2nd layer performs better
- Using the wrong fixed layer (e.g., 10th in subset #2) degrades performance
Implication:
- DoLa-static lacks generalizability and requires task-specific validation sets, which may not be feasible in real-world applications.
- In contrast, DoLa’s dynamic strategy (based on JSD) maintains robust performance across different subsets, achieving near-best results without tuning for each dataset.
Efficiency Comparison:
- DoLa-static: Requires 16–40 validation tests (one per layer) to find the best one
- DoLa: Only needs 2–4 bucket tests → ~10x fewer
Random Baseline Comparison:
-
Randomly selecting a premature layer performs worse than using no contrast at all, proving that:
JSD-based dynamic selection is essential for DoLa’s effectiveness.
⏱ 4.2 Latency & Throughput
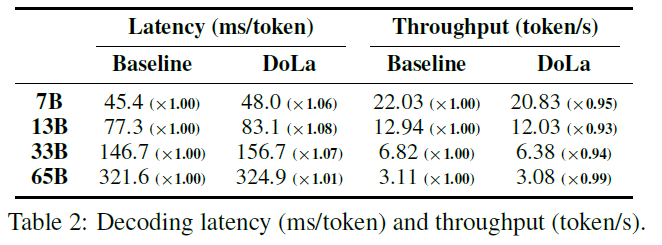
Result:
- DoLa introduces only a small latency overhead during greedy decoding:
- 1.01× to 1.08× increase in decoding time
- Memory/inference costs are discussed in Appendix E/F
Implication:
DoLa is practically deployable with minimal computational overhead.
✨ 4.3 Qualitative Study
TruthfulQA Examples (LLaMA-33B, Greedy Decoding):

- Q1: DoLa gives the correct historical fact
- Q2: DoLa avoids false but plausible information
- Q3: DoLa fails, prioritizing informativeness over accuracy
GPT-4 Evaluation:
- DoLa’s text generation quality was further assessed via GPT-4 (see Appendix D).
- Results indicate that DoLa improves qualitative output even in human-aligned evaluation.
Generalizability Beyond LLaMA:
- Applied DoLa to MPT-7B (MosaicML model)
- Found consistent performance improvement, indicating that DoLa generalizes across LLM architectures, not just LLaMA
Related Works
Hallucinations in LLMs
- Hallucinations refer to LLMs generating outputs not grounded in training data or real-world facts.
- Common causes: imperfect learning objectives, inadequate decoding strategies.
- Existing mitigation strategies:
- RLHF: Reinforcement learning from human feedback (e.g., Ouyang et al., 2022)
- Inference-time checks: Self-consistency (Manakul et al., 2023), multi-agent debate (Du et al., Liang et al., 2023), and inference-time interventions using labeled data (Li et al., 2023)
Transformer Layer Behavior
- Studies show layer-wise modularity in transformers:
- Early layers: focus on syntax
- Later layers: encode semantics and factual knowledge (Tenney et al., 2019)
- Recent work reveals:
- Topmost layers and specific heads play key roles in factual prediction (Meng et al., Dai et al., Li et al., 2023)
- Layer behavior varies by task and training objective (Fayyaz et al., 2021; Niu et al., 2022)
Contrastive Decoding (CD) and Variants
- Contrastive Decoding (CD) (Li et al., 2022):
- Contrasts expert and amateur models to improve fluency and coherence.
- Focused less on factuality, and more on style/fluency.
- Requires two models (expert and smaller amateur).
- DoLa’s contrast:
- Happens within the same model (e.g., different layers)
- Dynamically selects early layers based on token complexity
- More efficient (no extra model, no training, just early exits)
Other Related Methods
-
Context-Aware Decoding (CAD) (Shi et al., 2023):
Focuses on better context handling for summarization/knowledge conflict.
-
Autocontrastive Decoding (ACD) (Gera et al., 2023):
Similar to DoLa-static but uses small LMs (e.g., GPT2) with fine-tuned early layer heads.
- Aims for diversity/coherence, not factuality
- Found to increase hallucinations, unlike DoLa
Conclusion and Limitations
Contribution
- Introduced DoLa: a simple, inference-time method that improves factuality by:
- Contrasting hidden states from early vs. late layers
- Dynamically selecting contrast layers using JSD
- Key advantages:
- No need for external retrieval or additional training
- Generalizable across tasks and model families
Limitations
- Narrow focus on factuality:
- Does not explore synergy with methods like RLHF.
- Inference-only method:
- Relies on frozen, pre-trained models with no label-based fine-tuning.
- No external grounding:
- Cannot correct hallucinations rooted in training data errors because it doesn’t retrieve or verify with external sources.